近期�����,我校有3篇論文被國際計算機視覺與模式識別領(lǐng)域CCF A類會議IEEE CVPR 2025錄用���,這是我校首次在計算機視覺領(lǐng)域國際頂會CVPR上取得重要論文突破。論文由數(shù)智研究院和信息學(xué)院聯(lián)合西安電子科技大學(xué)�、墨爾本大學(xué)、西澳大學(xué)����、澳大利亞國立大學(xué)等單位合作完成,長安大學(xué)為第一作者和通訊作者單位���。
錄用論文簡要介紹如下:
1.Mono3DVLT: Monocular-Video-Based 3D Visual Language Tracking
該研究首創(chuàng)單目視頻三維視覺語言跟蹤(Mono3DVLT)研究���,突破傳統(tǒng)技術(shù)依賴昂貴傳感器及語言融合不足的局限���。團隊提出三大創(chuàng)新:定義單目視頻三維視覺語言跟蹤任務(wù)范式;構(gòu)建首個大規(guī)模數(shù)據(jù)集Mono3DVLT-V2X��,融合大模型生成與人工標(biāo)注�,提供79,158段含2D/3D標(biāo)注的自然語言視頻;開發(fā)多模態(tài)架構(gòu)模型Mono3DVLT-MT�,其創(chuàng)新設(shè)計的特征提取與融合機制在自建數(shù)據(jù)集上建立性能新基準(zhǔn),顯著超越現(xiàn)有方法�����,為三維視覺語言跟蹤領(lǐng)域提供突破性解決方案�。
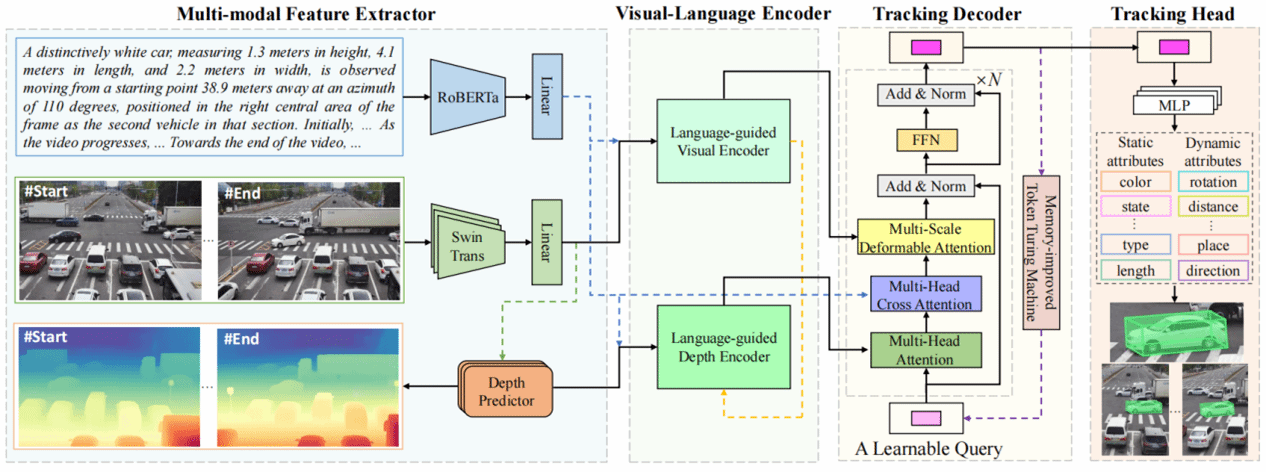
Mono3DVLT框架示意圖
2.Beyond Human Perception: Understanding Multi-Object World from Monocular View
該研究首次聚焦并深入研究了單目視覺下的三維場景理解難題:通過構(gòu)建具有空間感知能力的視覺-語言聯(lián)合表征模型,突破傳統(tǒng)單目視覺系統(tǒng)在復(fù)雜場景理解中的維度缺失瓶頸�����。針對現(xiàn)有方法在跨模態(tài)對齊和空間推理方面的不足�����,研究團隊創(chuàng)新性地提出基于狀態(tài)提示的視覺編碼器(SPVE)和去噪對齊融合(DAF)模塊����,有效解決了單目圖像深度信息缺失帶來的幾何歧義問題,實現(xiàn)了對多物體三維空間關(guān)系的精準(zhǔn)定位��。實驗表明���,該方法在自建的MonoMulti3D-ROPE數(shù)據(jù)集上相比現(xiàn)有最優(yōu)模型提升顯著����,平均定位精度達到72.3%�,較基線方法提升19.6個百分點。
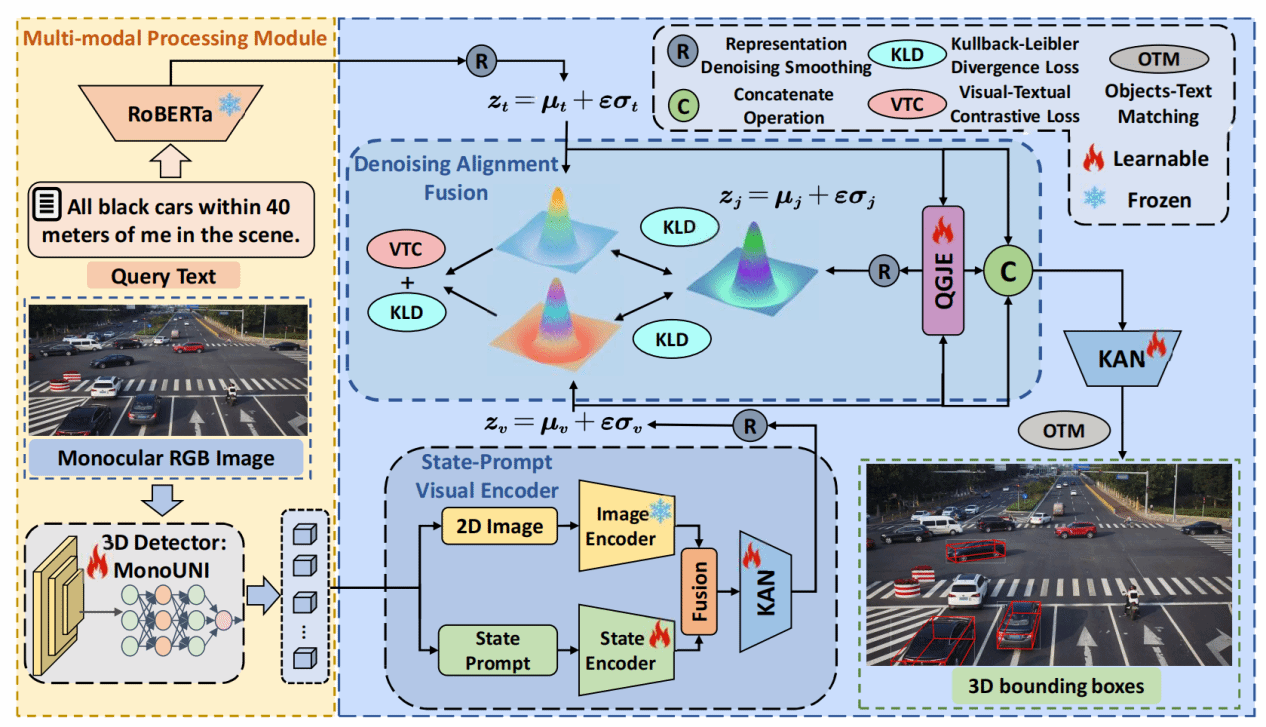
CyclopsNet模型架構(gòu)示意圖
3.Brain-Inspired Spiking Neural Networks for Energy-Efficient Object Detection
該研究首次聚焦并深入研究了類腦可解釋神經(jīng)網(wǎng)絡(luò)模型��,利用脈沖神經(jīng)網(wǎng)絡(luò)(SNN)豐富的動態(tài)特性構(gòu)建用于視覺任務(wù)的高效目標(biāo)檢測模型(MSD)���。提出一種全新的視神經(jīng)核團(ONNB)模型���,采用脈沖卷積神經(jīng)元作為核心組件,用于顯著增強SNN的深度特征提取能力�����。此外�,提出一種多尺度脈沖檢測框架來模擬生物對不同物體刺激,融合不同深度的特征和檢測響應(yīng)結(jié)果�����,實現(xiàn)靜態(tài)圖像和事件數(shù)據(jù)的高性能和高效處理。在公共數(shù)據(jù)集上的實驗表明���,MSD 取得了優(yōu)異的性能�����,同時減少了82.9%的能量消耗�。
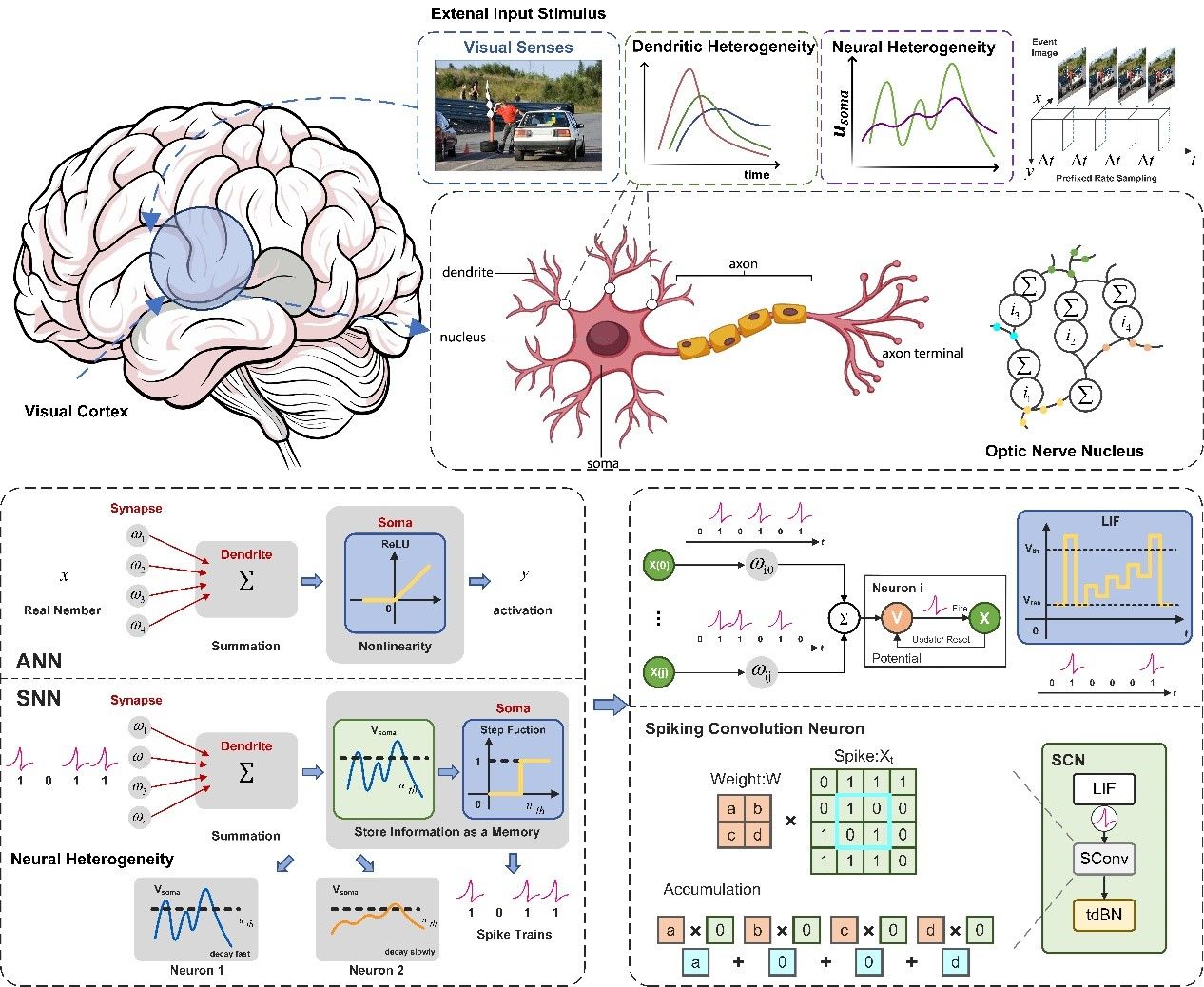
視覺刺激圖解與可訓(xùn)練神經(jīng)元模型SCN示意圖
CVPR是由IEEE主辦的計算機視覺及人工智能等領(lǐng)域最具影響力和最重要的國際頂級會議之一��。此次會議共有13008份有效投稿并進入評審流程���,其中2878篇被錄用�����,最終錄用率為22.1%��。
(審稿:高濤 網(wǎng)絡(luò)編輯:和燕)






